Finch Performance Lessons
With respect to a good tradition, I’m publishing a blog post based on my ScalaMatsuri talk covering a few performance lessons I learned working on Finch. Even though these lessons are coming from a foundation library, I tend to believe they can be projected into any Scala (or even Java) codebase no matter if it’s an HTTP library or a user-facing application.
10%
When it comes to throughput, Finch has been doing quite well compared to other Scala HTTP libraries. However, the absolute metric like QPS isn’t necessary the most interesting one. Historically, Finch has been measuring its performance (the throughput) in terms of overhead it introduces on top of Finagle, its IO layer.
We’ve been constantly measuring this kind of overhead locally, running a wrk load test against two different instances: Finch and Circe vs. Finagle and Jackson. This way we’re not only measuring Finch’s overhead, but also comparing two ends of the spectrum: type-level vs. runtime-level solutions.
Even though we’ve been doing this comparison for a while, no third party has ever tried to reproduce it until this very recent round of the TechEmpower benchmark.

According to the “Framework Overhead” (see above) comparison table, Finch performs on about 90% of Finagle’s throughput making it only/as much as 10% in terms overhead. Obviously, this overhead will hardly be noticeable for most of the services and yet could easily be a deal breaker for under-provisioned applications. This is why it’s important to understand from where these 10% are coming from and see if there is a way to reduce the gap.
Why only 10%?
In a typical Finch application lots of work is happening at compile time (think of Circe’s generic derivation and Shapeless’ machinery empowering endpoints). Turns out it might be a good deal to trade of complication time for (usually) safer and cheaper runtime.
As far as the JSON encoding/decoding goes, instead of inspecting each object at runtime to figure out how to properly encode/decode it, Circe’s encoders/decoders are already materialized once program compiled hence are ready for use at runtime. This not only makes codecs safer such that it’s known at compile time if they weren’t derived properly but also cheaper to use.
Besides taking an advantage of compile-time derived codecs for JSON, Finch is always trying to get the most out of the setup it’s currently running on. This includes using the most efficient decoding/encoding strategy depending on what JSON library is wired in and/or what Netty version is Finagle using at the moment.
Why as much as 10%?
It’s not a surprise that composition comes with a cost in a form of allocations and it’s somewhat fundamental. In the object-oriented setting, a new behavior is usually implemented as a class extending some old behavior. This way it’s possible to access a newly introduced logic by just instantiating this new class with a penalty of a single allocation.
In the functional (or even purely functional) setting, on the other hand, in order to introduce a new behavior to an existing entity, the later should be instantiated anyway before it gets composed with some other entity making the changes. This literally doubles the number of allocations used in a program promoting composition over inheritance.
Allocations Matter
High allocation rate itself isn’t a big problem on modern JVMs, and in fact, quite often is mitigated by JIT automatically moving some allocations on stack. However, this only possible for “local” and short-lived allocations that are never tenured. While it’s nearly impossible to tell what allocations will be eliminated (stack-allocated) by just looking at the source code, a good rule of thumb would be always consider the worst outcome and pretend that all allocations will go on heap and will live long enough to be compacted (copied over to prevent heap fragmentation). In other words, it’s generally a good idea to avoid all sorts of allocations as long as it doesn’t regress the throughput. The bottom line is lower allocation rate will often pay back with less frequent and shorter GC pauses.
Allocation profiles are even more important for the foundation libraries like Finch or Circe. Libraries that are always placed on application’s hottest path, transforming a request into an appropriate response. Just a hundred of bytes allocated on the request/response path will sum up into several hundred megabytes of memory allocated and deallocated every second once service’s QPS hits reasonably high numbers.
Allocating Less
Paying attention to the allocation profile is one of the essential skills needed for writing GC-friendly programs. Even though Scala code is quite hard to reason about performance-wise, it’s mostly easy to guestimate how many bytes a given code structure is going to allocate. It just requires some practice made up of experiments with JMH’s -prof gc mode.
While this byte counting business may seem too low-level and possibly worthless, the idea of allocating less scales really well from the scope of a single function to the entire program. We’ll see later in this post how both local and global optimizations of the allocation profile, recently made in Finch, help to improve the throughput.
Composing Less
Intuitively, one way of saving allocations is giving up on composition. This doesn’t necessary mean dropping down to the object-oriented concepts in the user-facing API but rather revisiting the internal structures along with making sure they are not engaging composition/allocations. Even though, adopting ideas like inheritance, mutable arrays, and while loops considered impure, it’s quite a popular trade-off to make in the foundation libraries including those promoting a purely-functional API.
When it comes to modeling an endpoint’s result, Finch has been using the type alias to an option indicating whether or not the endpoint was matched on a given input.
type EndpointResult[A] = Option[(Input, Future[Output[A]])]This worked perfectly well in the past given how idiomatic and easy to reason about it is. However, this introduces an unnecessary overhead coming from an abstraction that’s way more powerful than needed. As any other abstraction from a standard library, Option comes with a variety of combinators that promote an idiomatic usage pattern based on either for-comprehension or map and flatMap variants. There is absolutely nothing wrong with those functions except for the cost they’re coming with, which could be a deal breaker for performance-critical abstractions. Most of the time, mapping an option means allocating a closure that depending on the number of arguments may be quite expensive.
In addition to that, on the successful path (when an endpoint is being matched and the result is being returned), it requires two allocations to get the result out of the door: one for the inner Tuple2, one for the outer Option.
An alternative to the Option solution would be to hand-roll our own abstraction that basically acts as a flattened version of Option[Tuple2[_, _]] such that it only requires a single allocation to instantiate a successful result.
sealed abstract class EndpointResult[+A]
case object Skipped extends EndpointResult[Nothing]
case object Matched[A](rem: Input, out: Future[Output[A]]) extends EndpoinResult[A]An important difference between those two approaches is in the signal their APIs are sending to the users. An API that engages composition isn’t always appropriate as a meaning for an internal abstraction living on a hot execution path. A bare-bones ADT exposing nothing but patten-matching (which costs almost nothing in Scala) as its API could be way more suitable for this kind of business.
As far as the benchmarking goes (see table below), saving around 56 bytes on a single Endpoint.map call make it up to 5% improvement in terms of throughput (see #707).
---------------------------------------------------------------------------------------------
TA: Type Alias | ADT: sealed abstract class | Running Time Mode
---------------------------------------------------------------------------------------------
MapBenchmark.mapAsyncTA avgt 429.113 ± 43.297 ns/op
MapBenchmark.mapAsyncADT avgt 407.126 ± 12.807 ns/op
MapBenchmark.mapOutputAsyncTA avgt 821.786 ± 52.045 ns/op
MapBenchmark.mapOutputAsyncADT avgt 777.654 ± 26.444 ns/op
MapBenchmark.mapAsyncTA:·gc.alloc.rate.norm avgt 776.000 ± 0.001 B/op
MapBenchmark.mapAsyncADT:·gc.alloc.rate.norm avgt 720.000 ± 0.001 B/op
MapBenchmark.mapOutputAsyncTA:·gc.alloc.rate.norm avgt 1376.001 ± 0.001 B/op
MapBenchmark.mapOutputAsyncADT:·gc.alloc.rate.norm avgt 1320.001 ± 0.001 B/opIntroducing a new abstraction/type into a domain is always a trade-off and yet an easy one to make in this particular case. With a cost of a little of the maintenance burden, we get a less powerful and more performant abstraction that’s really hard to misuse.
Encoding/Decoding Less
Avoiding all sorts of allocations isn’t necessarily a local optimization, but can be applied globally to the scope of the entire program. Consider a typical HTTP application that serves JSON. Certainly, most of the allocations in such application are coming from JSON decoding and encoding such that instead of using the payload right away (in whatever form it is) we need to convert it into a JSON object first.
Presumably, JSON encoding and decoding aren’t something that could be easily avoided in the HTTP application exposing JSON APIs. This is a rightful workload for this kind of applications. However, there are certain stages (involving allocations) within the data transforming pipelines that might look mandatory and yet could be completely eliminated.
As far as the JSON decoding goes, there are at least two data transformation stages involved. After getting the bytes of the wire, we typically convert them into a JSON string (a UTF-8 string) instead of shoving them right away into a JSON parser. Whereas going from bytes to string (i.e., new String(bytes)) may seem pretty cheap, it actually involves quite a lot of allocations along with CPU time needed for memory copy. Instead of wrapping a given byte array with a String, JVM copies it over into a newly allocated char array of the same size thereby doubling the allocations (char takes 2 bytes on the JVM).
All of this sounds pretty frustrating given that, in most of the cases, the only reason we actually need a string (and not the bytes) is to satisfy the API of the used JSON library. Good news is lots of modern JSON libraries allow to skip this unnecessary to-string conversion and parse JSON objects directly from bytes (see below).

As of Finch 0.11 (see #671), for all the supported JSON libraries, the decoding of inbound payloads doesn’t involve any interim to-string conversions and is done in terms of bytes. In our end-to-end benchmark, this optimization alone accounts for 13% improvements in the throughput.
When it comes to micro-benchmarking, decoding from bytes instead of a string cuts both allocations and running time in half (see below) making it a pretty great deal given how small and simple the change is.
---------------------------------------------------------------------------------------------
S: parse string | BA: parse byte array | Running Time Mode
---------------------------------------------------------------------------------------------
JsonBenchmark.decodeS avgt 5950.402 ± 464.246 ns/op
JsonBenchmark.decodeBA avgt 3232.696 ± 171.160 ns/op
JsonBenchmark.decodeS:·gc.alloc.rate.norm avgt 7992.005 ± 12.749 B/op
JsonBenchmark.decodeBA:·gc.alloc.rate.norm avgt 4908.003 ± 6.374 B/opA similar optimization is also possible on the outbound path. It might be worth trying to skip the unnecessary string representation and print directly into a byte array (see below). By analogy from converting a byte array into a string, converting a string into a byte array also involves a surprising amount of allocations. Because it’s not known beforehand how many bytes a given string is going to occupy, JVM is trying to guestimate that as 3 * string.length, where 3 is the maximum numbers of bytes needed for a single UTF-8 character.
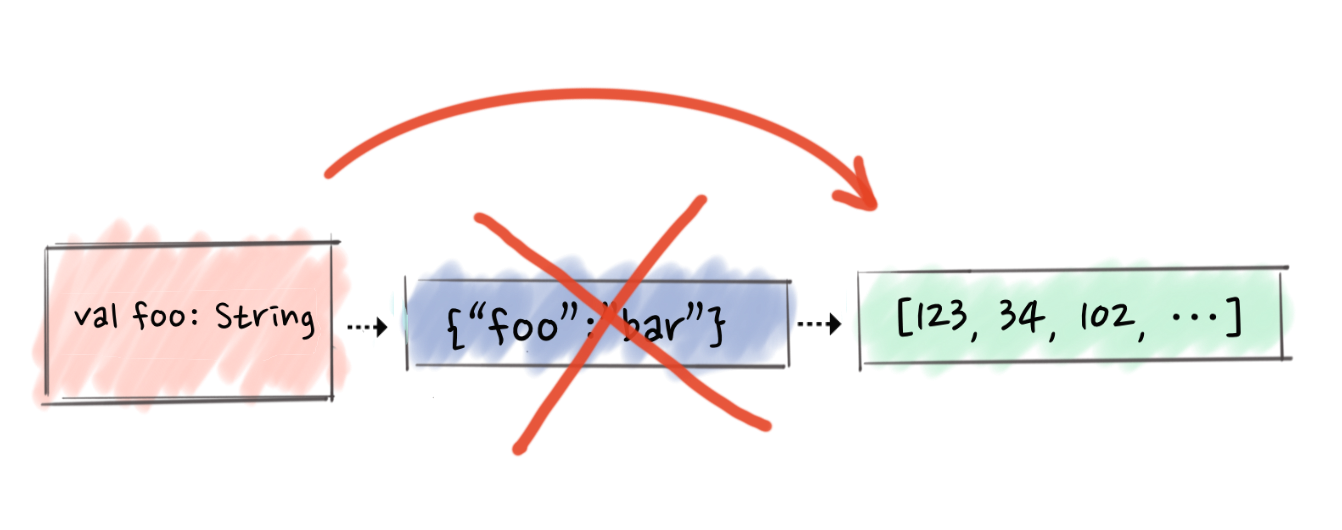
Printing JSON directly into a byte array isn’t so common as parsing bytes and only a couple of JSON libraries support that. As of Circe 0.7 (see #537) and Finch 0.12 (see #717) it is a default JSON encoding mode for applications depending on finch-circe (including those using circe-jackson for printing, see #11).
The encoding benchmark we run for JSON reports about 30% drop in both allocations and running time when targeting byte arrays instead of strings (see below).
---------------------------------------------------------------------------------------------
S: print string | BA: print byte array | Running Time Mode
---------------------------------------------------------------------------------------------
JsonBenchmark.encodeS avgt 16400.327 ± 621.935 ns/op
JsonBenchmark.encodeBA avgt 12645.070 ± 391.591 ns/op
JsonBenchmark.encodeS:·gc.alloc.rate.norm avgt 46900.015 ± 19.123 B/op
JsonBenchmark.encodeBA:·gc.alloc.rate.norm avgt 30360.011 ± 0.001 B/opThe main point here is not that string to bytes and bytes to string conversions aren’t really cheap on JVM (they are as cheap as they could be) but rather aren’t always necessary. The tricky part is that it often requires us to look at the problem end-to-end to figure what data transformations (as well as interim results) don’t add much value to the domain and can be eliminated.
Takeaways
“This is slow” is one of the toughest problems to debug. Although, always paying attention to the allocation profile is quite a healthy habit allowing to reduce the number of performance-related problems to their minimum. Despite all the great tools available for chasing down allocations (think of JMH’s -prof gc), none of them are going to tell us if there are any shortcuts our application can take to get the final result faster.


