Finagle 101
This post is based on my talk “Finagle: Under the Hood” that was presented at Scala Days NYC. I thought I’d publish this for those who prefer reading instead of watching (video is not yet published anyway). The full slide deck is available online as well.
What Finagle is?
![]()
Finagle is an RPC system for JVM developed and used in production at Twitter. It’s written in Scala but has a Java-compatible API for most of its components.
When it comes to describing what Finagle can do, I really like Alexey’s tweet from the last FinagleCon.
The key problem with #Finagle adoption that it solves tons of problems that you know nothing about until it's too late #FinagleCon
— Alexey Kachayev (@kachayev) August 13, 2015
The most important part here is: “Finagle solves tons of problems”. And it absolutely does. There are many different things (a user doesn’t know about) happening underneath a Finagle client or a server to make sure sessions are reliable enough. Finagle is doing a great job at tolerating all kinds of session and transport failures so its users usually don’t even notice neither failures nor actions Finagle is taking to tolerate them.
Finagle’s been around for quite a long time - since 2010. With 4.5k stars, it’s the 7th most popular Scala project on Github. As for today more than 15 protocols are implemented, including our own multiplexing protocol Mux. Mux is a full-duplex, multiplexing protocol that might be roughly viewed as a subset of HTTP/2 so it has low-level control messages for pings, interrupts, and many more. We will see later how we utilize those signals within Finagle.
Finagle has quite a specific mission to make RPC sessions fast, resilient, and easy to setup. Operating on Layer 5 of the OSI model, Finagle knows almost nothing about the application and even protocol it’s used by. That’s why it doesn’t actually answer lots of application-specific questions like “How to do logging?”, “How to do JSON?”, “Where to define a REST controller?”. To fulfill that gap and utilize Finagle’s outstanding scalability and performance, people started building opinionated libraries and frameworks that are supposed to answer all those question. Just to mention a couple of such libraries specifically designed for HTTP: Finatra and Finch.
The Finagle team at Twitter is called CSL (Core System Libraries). There are ~10 of us maintaining libraries that power Twitter’s distributed infrastructure. We own Finagle, Util, Scrooge, TwitterServer and Finatra. We’ve got on-call rotation and internal finaglers we use to provide support for teams dealing with production issues related to Finagle.
Internally Finagle lives in a monorepo and services depend on its source code. Essentially, every time we do an OSS release, we actually roll out the code that has been already tested internally for months (by thousands of services serving millions or RPCs every second), which sounds like a pretty decent deal for external adopters.
The “Big Picture”
Finagle is designed with this simple idea in mind that your server is a function. This means you can talk to that server by calling this function and you can implement that server by defining this function.
trait Service[Req, Rep] extends (Req => Future[Rep])The most exciting part here is those type params Req and Rep meaning that your service (server or
client) is actually abstracted over the particular protocol (particular request/response types).
This gives us a freedom to build most of the generic features like retries in the protocol-agnostic
way, not mentioning that types add some safety into your code. For example, it’s impossible to send
an HTTP request to a MySQL - compiler will catch that.
This is how Finagle is organized internally. There are three major components it’s built on: Finagle stack on a left, Netty pipeline on a right, and transport in between.
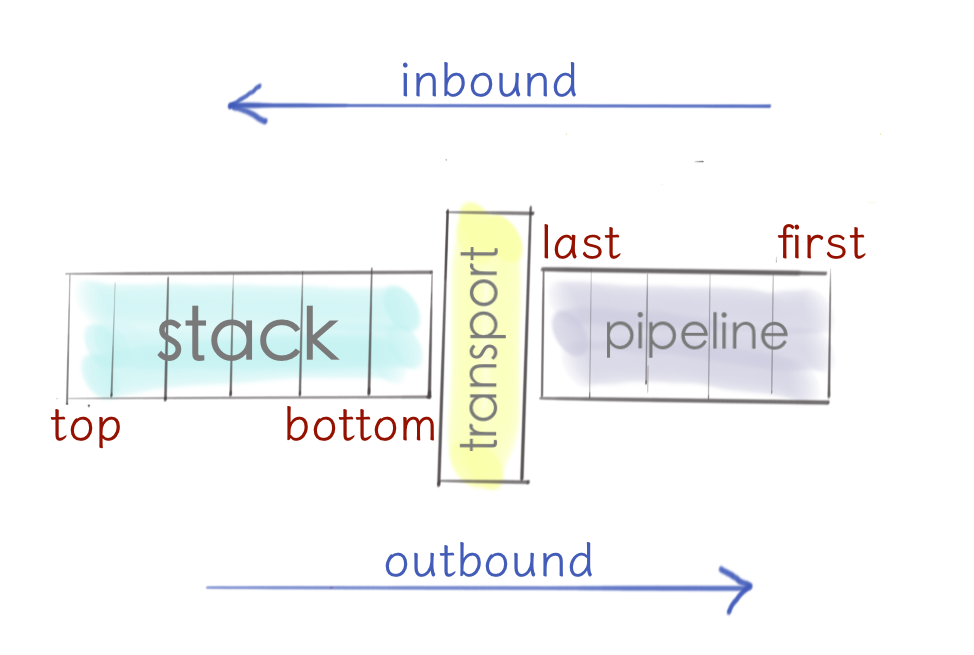
This is a really interesting combination: we’ve got two completely different worlds here. The service-oriented, type safe, powered by composition and functional abstractions Finagle world on the left. And event-based, untyped, low-level Netty world on the right. And transport glues them together.
We will cover the left part here in this post. The Finagle stack is our generic abstraction used to materialize Finagle clients and servers out of a composition of ordered modules, which may be anything that is known how to compose. And we know how to compose services (since they are just functions). Technically we can put those services/functions into a stack and materialize it into a client or server. That’s pretty much what we do in Finagle today. If you speak functional programming, we fold a collection of modules into a client or server.
Each module in the stack represents some standalone functionality like retries, load balancing, circuit breaking and so on. And in fact, this is exactly how Finagle server looks like - it’s simple and flat. Clients are quite tricky on the other hand.
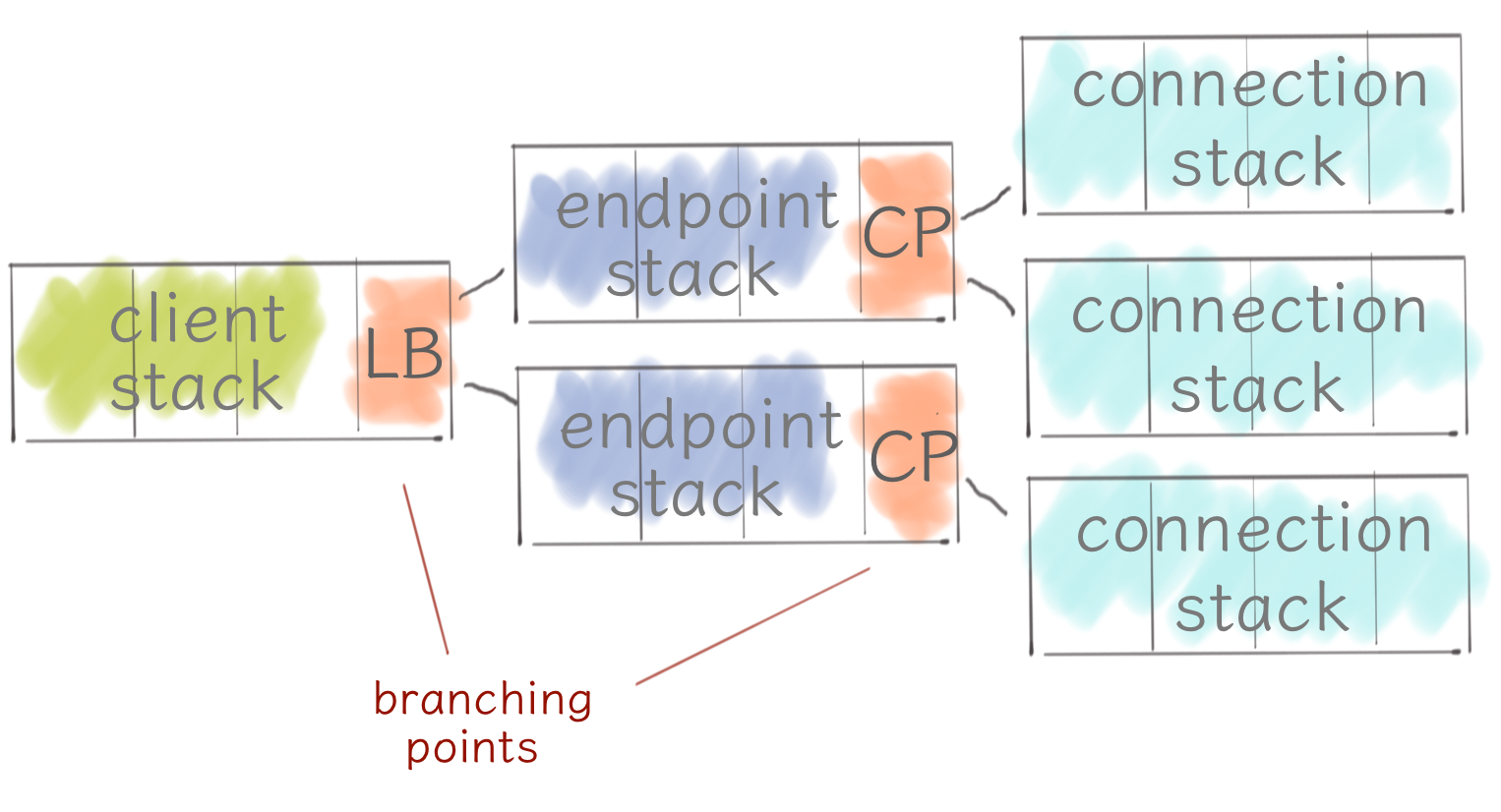
There is a actually a tree of stacks in the client with two branching points. First, a load balancer distributes traffic across a number of nodes or endpoints. Second, a connection pool, maintains a pool of connection stacks, which terminate with transport and a Netty pipeline.
Configuration
Before we go deeper into details about client/server modules, let’s discuss what they have in common - a configuration API. To be fair, that’s one of my favorite topics because I think it’s a really tricky problem to build a configuration API that’s both easy-to-use (common things should be easy to do) and powerful-enough (uncommon things should be possible to do). The current version of configuration API in Finagle is the third iteration of an idea that configuration is a code.
Configuration is always code (not CLI flags, not config files) in Finagle so it type-checks by your
compiler and auto-completes by your IDE. There is a convention on how to find an entry point API
depending on the protocol you want to work with. Usually, you start with typing something like
Http.client.with and see what’s possible to configure/override on a given client. We separate
commonly-configured params from the ones we think it might be dangerous to tweak today. We call those
expert-level and use slightly different API to override them. The expert-level API is
usually not so friendly and discoverable as with-API, which works perfectly as a red flag:
if you’re not having a good time writing configuration, you’re probably doing something wrong or
dangerous.
Servers
Servers are quite simple in Finagle. They are optimized for high-throughput by doing as little as possible on top of just handling requests. At the minimum, a Finagle server does tracing and metrics, maintains request concurrency level and enforces a very simple request handletime timeout.
Here is an example of how you can configure the concurrency limit on your server. You can say how many concurrent requests your server can handle at once and how many waiters are allowed. Everything on top of that will be rejected by a server and hopefully retried by a client talking to our server.
import com.twitter.finagle.Http
val server = Http.server
.withAdmissionControl.concurrencyLimit(
maxConcurrentRequests = 10,
maxWaiters = 0
)Concurrency limit is one of the forms of admission control we have for servers. Admission control is a technique that employs some kind of feedback controller from the underlying system to determine whether it’s reasonable to handle (for servers) or send (for clients) a given request or it’s better to reject it. As a canonical example of server-side admission control, we might think of something that prevents a server from overwhelming by rejecting some amount of requests. Essentially, instead of slowing down 100% of requests we reject, for example, 25% but keep operating normally (and maybe even stay within the SLOs).
Request timeout is symmetric and might be configured on both servers and clients. It literally means the same thing: timeout requests for which responses weren’t sent (when configured on a server) or received (when configured on a client) in a given amount of time.
import com.twitter.conversions.time._
import com.twitter.finagle.Http
val server = Http.server
.withRequestTimeout(42.seconds)There is no default value for request timeout and it’s disabled for the same reason concurrency limit is disabled. Finagle is trying really hard to not speculate on any application-specific (or even protocol-specific) params. You have to be explicit about those.
Clients
Clients are where things get interesting. Unlike servers, which are optimized for high throughput, clients maximize success rate and minimize latency by doing as much as possible to make sure a request will succeed in the least possible time. This makes them much more complicated than servers. The list of features clients do is quite dramatic for being fully covered here in this post, but we can surely walk through them and see what kind of problems they solve.
First of all, we need to be able to retry failed requests thereby maximizing success rate. Retrying implies a number of quite difficult questions we need to find answers to. How can we say if the request is failed? Is that safe to retry this request? If we already tried once and it didn’t help, should we keep retrying or should we give up? Finagle is taking a good care about all of these and we’ll see later what kind of abstractions it uses to achieve that.
Next, we need a way to help services locate each other so there is a built-in service discovery support in every Finagle client. By default, it might either use DNS or Zookeeper, but it’s also possible to plug in any other library by implementing a couple of simple interfaces. For example, there is an OSS package that enables Consul support in Finagle.
We also need a tooling around timeouts so we could put reasonable bounds on components in our distributed system. In addition to request timeout that we’ve already discussed, there is the hell of a ground of timeouts you can override in Finagle, starting with low-level TCP connect timeouts and finishing with session timeouts. None of the timeouts are bound by default since those values considered specific to a given application. Use the following example to override timeouts.
import com.twitter.conversions.time._
import com.twitter.finagle.Http
val client = Http.client
.withTransport.connectTimeout(1.second) // TCP connect
.withSession.acquisitionTimeout(42.seconds)
.withSession.maxLifeTime(20.seconds) // connection max life time
.withSession.maxIdleTime(10.seconds) // connection max idle timeOf course, we need to distribute traffic across a number of instances where our software is deployed. Finagle comes with a very rich set of load balancers and I honestly can’t name another system around that provides such advanced load balancing strategies as Finagle does today. We’ll cover load balancing in details later in this post since it plays a major role in resiliency of Finagle clients.
Besides picking a right replica to send request to, a Finagle client also takes care about managing connections pool as well as maintaining a stack of circuit breakers used to exclude unreliable replicas/sessions from a request path.
Clients are also come with interrupts support that is primarily used for request cancellation and prevents both servers and clients from doing useless work. You might think - “Why would I cancel the request? I sent it and I meant it!”. The tricky part here is that interrupts happen implicitly. Consider the following example. Your client sets a timeout and sends a request to a server. After a given amount of time a timeout expires and a client interrupts the future associated with a given request. What happens next is really depending on client’s protocol, but long story short, Finagle will do its best in order to propagate that cancellation across service boundaries. Worst case scenario - (i.e., HTTP 1.1) it cuts the connection but there is so much more we can do in Mux (and perhaps HTTP/2) by sending a control message to a server saying something close to “Hey, I’m no longer interested in the result of this request so you should feel free to drop it”.
Quite similarly to propagating interrupts, we might want to also do that for some request context that might contain quite useful (for debugging and monitoring/tracing) information like request id, request deadline, upstream/downstream service name and so on. Clients support that today and will take care about serializing/deserializing contexts depending on the used protocol (eg: request headers are used in HTTP) and propagating them across service boundaries.
Both interrupts and contexts are used heavily at Twitter and that’s one of the reasons why we still like our futures better. Unlike Scala futures, Twitter futures will propagate contexts and interrupts through the chain of transformations, no matter if its parts are executed by different threads.
Response Classification
As we discussed before, being on Layer 5 means knowing everything about transport and sessions, but nothing (or almost nothing) about protocol/application. This implies some unexpected behaviour when HTTP 500 (Service Unavailable) actually looks like a successful response to a Finagle client. The following poll proves that this is confusing at the minimum.
Quick poll by @kevino: Does Finagle treat HTTP 500 response as a failure or success?
— Finagle (@finagle) February 9, 2016
Why does that happen? Nothing magical. There is definitely nothing wrong with a correctly structured protocol message (eg: HTTP 500) from client’s point of view so it’s counted as a success. And that’s quite a big deal. First, we’ve got our metrics messed up: success rate is 100%, but we’re serving failures. Second, our load balancers go crazy. They think if a given server responds fast and the response is a success, it seems like a great deal to send it more traffic while it fact it was failing fast.
Since 6.33, we’ve got response classifiers that you can plug into any client and teach it how to treat responses. For example, here is how you can tell HTTP client see HTTP 503 as a non-retriable failure so the circuit breaker will kick in on this response.
import com.twitter.finagle.{Http, http}
import com.twitter.finagle.service._
import com.twitter.util._
val classifier: ResponseClassifier = {
case ReqRep(_, Return(r: http.Response)) if r.statusCode == 503 =>
ResponseClass.NonRetryableFailure
}
val client = Http.client
.withResponseClassifier(classifier)Retries
The retries module is placed at the very top of the stack so it can retry failures from the underlying modules (eg: circuit breakers, timeouts, load balancers). Finagle will only retry when it’s absolutely safe to do that. For example, when it’s known that a request wasn’t written to a wire yet, or when a request was rejected by a server. And this makes a lot of sense: if a load balancer picked a replica that rejected a request (eg: due to admission control) - it’s totally fine to retry that on a different replica.
Retries are built on top of retry budgets, which behave as leaky token buckets and tie a number
of retries to a total number of requests. Technically, RetryBudget is responsible for limiting a number
of retries and helps mitigating retry storms (i.e. retrying too much).
Once we’re given a permission for a retry by a retry budget, we’d need to figure out how long to wait
(if wait at all) between retries. This technique is called backoff in Finagle (and almost any other
library) and represented as Stream[Duration], which means you can easily plug in your own thing.
Finagle provides an API for building popular backoffs, including jittered, which are super useful in clusters built around optimistic locking whose individual nodes might perform poorly under the high contention. Our goal is to make sure that clients started at the same time are not competing with each other on retries to a single server. To do that we add some randomized factor (or jitter) into every duration from a backoff policy thereby reducing chances that several clients will be retrying simultaneously.
For example, that’s how we override retry budget and retry backoff on HTTP client. Budget allows 10%
of total request to be requeued on top of 5 requests per second to accommodate clients with low RPS.
Backoff uses jittered version of randomized function that grows exponentially
(eg: random(2s) :: random(4s) :: ... :: random(32s)).
import com.twitter.finagle.Http
import com.twitter.conversions.time._
import com.twitter.finagle.service.{RetryBudget, RetryBackoff}
val budget = RetryBudget(
ttl = 10.seconds,
minRetriesPerSec = 5,
percentCanRetry = 0.1
)
val client = Http.client
.withRetryBudget(budget)
.withRetryBackoff(Backoff.exponentialJittered(2.seconds, 32.seconds))Load Balancers
There are pretty deep-seated assumptions inside of Finagle that service clusters are homogeneous, that they are equivalent from the point of view of the application. Those are often referenced as a replica set.
In Finagle, load balancers consist of two independent components: load distributor and load metric. That said, the load balancing algorithm might be described in terms of those two: we distribute load across some subset of nodes/replicas and pick the one for which a load metric is minimal.
In order to better understand the variety of load balancing options available in Finagle today, let’s have a look at their evolution so we can see why they were introduced in the first place and what problems do they solve.
In the very beginning, we had this heap balancer built on top of min-heap that maintains the number of outstanding requests per each node. That worked really well and it was the default choice for a long time.
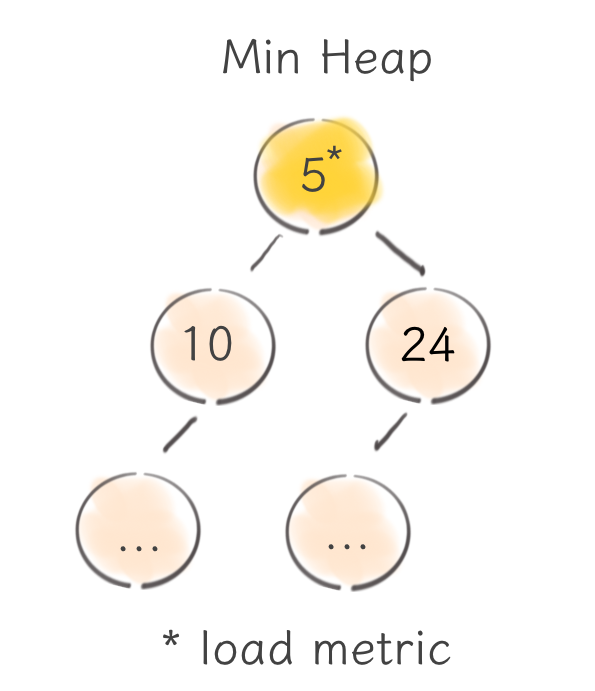
But at some point, we figured out a number of drawbacks this option had. First of all, a load balancer state (i.e., heap) is a highly contended resource (updated on each request) and it should support extremely fast updates. Needless to say, that heap is an amazing data structure and has constant time access to its min element, but every other operation takes the logarithmic time to perform. That’s why it’s tricky to implement a different and perhaps more sophisticated load metric on top of the heap without sacrificing its performance.
The next step was the P2C (power of two choices) load balancer that solved most of the heap balancer problems. By employing quite a brilliant idea, the algorithm takes two random nodes from the server set and picks the least loaded one. If we use that strategy repeatedly, we will get a manageable upper bound of the maximum load on each node.
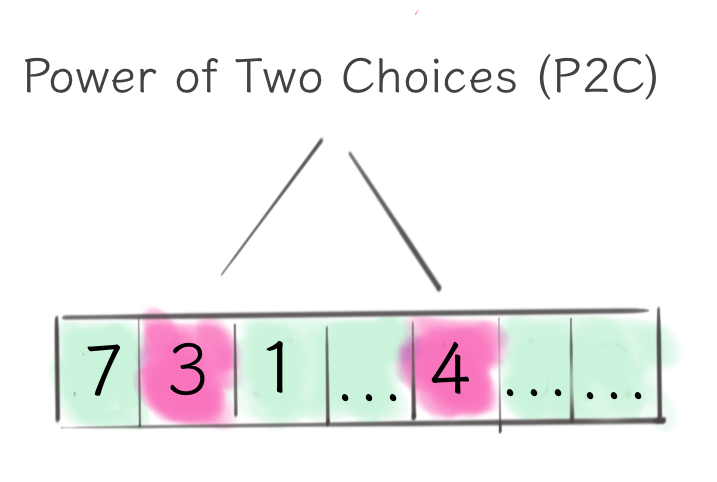
Given that we can now update the load balancer state in a constant time (by just updating the array), we can employ more sophisticated load metrics. The EWMA load metrics was Finagle’s next attempt in that direction.
Per each node in the server set, EWMA (stands for Exponentially Weighted Moving Average) keeps track of round-trip latency weighted by a number of outstanding requests. And this is really smart, because being on Layer 5, we can take an advantage of both RPC latency and RPC queue depth. This makes EWMA quite sensitive to latency spikes so it reacts much faster on GC pauses and JVM warmups. For example, if a load balancer happened to pick a replica that just went to a long GC pause, its EWMA metric will reflect that immediately and its load will be adjusted accordingly.
There is an outstanding post from @stevej on the comparison of three different load balancing options in Finagle that quite explicitly shows how EMWA outperforms all other options. EWMA shows the best result there in mitigating latency spikes caused by GC pauses or JVM warmups.
While EMWA looks very promising already, there is even more advanced load balancer in Finagle today. The aperture load balancer is designed to solve the problem of large server sets. Depending on a scale, each Finagle client might be talking to several thousands of servers, which will likely result in several thousands of opened connections and quite low concurrency per each node. Why does a number of connections matter? It’s waste of resources and it comes with a cost of long tail latency because of the high number of connection establishments. Why does concurrency matter? To take advantage of any load metrics we need some numbers to work with. When concurrency is low our least loaded metrics is zero for every server.
The aperture load balancer solves that by viewing the huge server set through a small window where it can apply any existing load balancer.
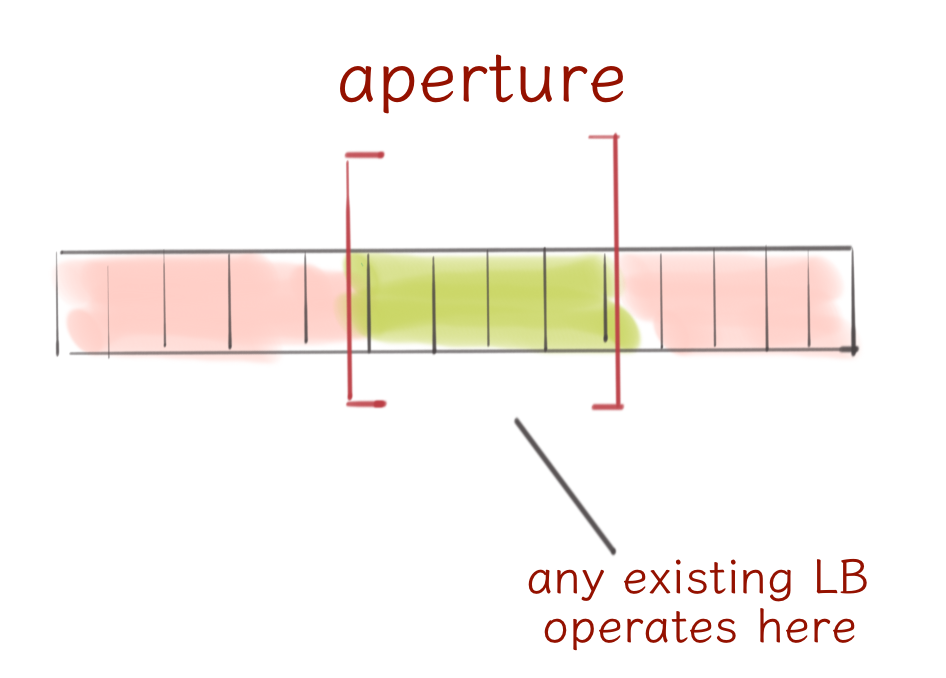
The advantages of aperture are quite promising. Fewer connections for clients and servers means better tail latency. Also, by employing a simple feedback controller, the load balancer adjusts the aperture size to maintain the requested concurrency level thereby keeping replicas in a warm state.
We will likely make aperture a default balancing option quite soon, but right now you’d need to enable it manually. Here we build the aperture load balancer with initial size 10 and load bounds between 1 and 2. Basically, this means that we want to make sure all replicas in aperture will be constantly getting between 1 and 2 concurrent requests and the aperture will be resized dynamically to satisfy that requirement.
import com.twitter.conversions.time._
import com.twitter.finagle.Http
import com.twitter.finagle.loadbalancer.Balancers
val balancer = Balancers.aperture(
lowLoad = 1.0, highLoad = 2.0, // the load band adjusting an aperture
minAperture = 10 // min aperture size
)
val client = Http.client.withLoadBalancer(balancer)Circuit Breakers
Now we know how load balancers distribute load, the question is how they avoid nodes that are likely to fail or already failed? This is done by a layer of circuit breakers placed under load balancers so that when they mark a replica unavailable, it will be avoided by a load balancer.
As of today, there are three circuit breakers in Finagle.
- Fail Fast - prematurely disables the session that failed TCP connect.
- Failure Accrual - performs liveness detection on a request basis.
- Threshold Failure Detector - a ping-based failure detector that periodically measures RTT latency for ping-pong exchange between nodes and if the latency doesn’t look good, it excludes that session from a request path. This is a pretty powerful tool, but it requires the underlying protocol to support liveness detection control signals. For now, we have that implemented for Mux and will likely do that for HTTP/2 as well.
Failure Accrual is our the most advanced circuit breaker in the way that it supports a pluggable policy used to determine when to mark a session unavailable. Today it’s possible to either configure it to maintain a required success rate (if that goes below a requested value, a session is marked dead) or you can say after how many consecutive failures a session is considered unavailable.
By default, it’ll mark a session dead after 5 failures in row and go to a jittered backoff before re-enabling that session/or replica again. Although, it’s quite easy to override that to be success rate-based and disable the session once its success rate is below 95% on the most recent hundred of requests.
import com.twitter.conversions.time._
import com.twitter.finagle.Http
import com.twitter.finagle.service.{Backoff, FailureAccrualFactory.Param}
import com.twitter.finagle.service.exp.FailureAccrualPolicy
val twitter = Http.client
.configured(Param(() => FailureAccrualPolicy.successRate(
requiredSuccessRate = 0.95,
window = 100,
markDeadFor = Backoff.const(10.seconds)
)))What’s next?
There are quite exciting times ahead. Netty 4 migration is on track and should happen really soon. I know we’ve been promising this Netty 4 utopia for about two years now, but we’re finally getting there.
What Netty 4 means for Finagle? First, we expect better performance/fewer allocations. Second, support for new protocols (like HTTP/2). Third, simplification of Finagle internals due to simpler and safer threading model in Netty 4. Finally, it’s better to stay aligned with the state of the art IO library for JVM to get the maximum of it.
We’ll also continue working on resiliency and admission control in Finagle to make sure we’re doing as much as possible to make your RPC sessions even more reliable and easy to configure.


